SCRAPEGMAPS, SCRAPEWEBS, and VERIFYEMAILS are powerful industrial software for scrape, extract and verify bulk of
potential contact data, with input search keywords targeted by product name or industry name, and targeted location.
The software have been designed for operating with unlimited number of threads to optimize speed for scraping/extracting/verifying a
bulk of data in a short time. It is highly recommended to build a workstation computer with large number of CPU thread numbers to exploit
the software with the highest efficiency. Large amount of memory (RAM) and high speed disk storage (SSD) are also recommended use. We have
tested the software with different hardware configurations to get the highest efficiency with the most saving cost, this is a good
suggestion
*:
-
CPU:
Xeon E5-2600 V4 Family(Suggested models 2650, 2660, 2680, 2683, 2690, 2695, 2697, 2698 with 24~48 threads per CPU).Xeon E5-2600 V3 FamilyorXeon E5-2600 V2 Familyalso working good with models which have high threads number, they are cheaper but cost more power and always higher temperature when operating. -
Motherboard:
HUANANZHI X99-F8D Plus(Support dual Xeon CPU).Supermicro X10DRL-iorX10DAL-iare better options but cost more. HUANANZHI is a motherboard brand from China, is the cheapest option but good enough (We have used it through over a year without any problem), Supermicro is a more reputable brand in supply datacenter hardware so you can choose it if you don't care about build cost. - RAM: 128GB ~ 256GB depend on the number of CPU thread suggested above (This is only suggestion for SCRAPEGMAPS software which run multiple built-in web browsers in background for scraping. SCRAPEWEBS, VERIFYEMAILS use less memory).
- SSD: 512GB ~ 1TB is good enough.
- VGA/GPU:
Nvidia GeForce GTX-1080/RTX-2080or higher/newer-models.
(
*) This suggestion is good enough to run our software with save built cost. If you want higher speed or run heavier
workload and don't care about build cost, you can use high-model XEON E7 CPU which is same number of thread as above
XEON E5 CPU suggestion but can run with motherboards which have 4 CPU sockets or 8 CPU sockets, or use Intel Xeon scalable
newer models. More threads mean more workload so it also requires more more memory with higher speed, VGA/GPU also requires
higher-model if process always takes over 80% of its efficiency.
(
**) There is no problem if you cannot prepare hardware as the above suggestion. Our software still can run with lower
hardware configuration, but it will run with lower efficiency. If your hardware configuration is too low, our software will run at the
minimum efficiency with 10 scraping/verifying threads (with the verifyemails software, which requires proxy to run, it may
less than 10 threads if you provide less than 10 proxies).
-
Operating System (OS):
Windows 10 Pro 64bit,Windows 10 Pro for Workstation 64bit, orWindows 11 Pro 64bit.Windows 10OS is strong recommended because we have tested our software mostly inWindows 10OS and it is stable.Windows 11OS is also worked, but we are not test much time so it is not confirmed to work stable, if you use the software inWindows 11OS and find any bugs, please contact us to fix it and release an update patch. -
Caching Server: Our software used
RedisandMemcachedcaching technology for optimizing its efficiency, so it is required to install a caching server, config the connection from our software to this caching server and start the caching server before run our software. If you are not professional in IT, don't worry because we have prepared an easier solution for you: you can use ourpre-installed caching serverwhich can run throughDocker ContainerusingDocker Desktopsoftware and it is very easy to do, also no need to re-config our software. This is totally a free solution, you don't need to pay more money for it. Here is the detail instruction how to install and use ourpre-installed caching server:-
Download
Docker Desktopfrom https//www.docker.com/products/docker-desktop: Select and Download version forWindows 64bitthen install it. - Restart computer as the requirement after installed
Docker Desktop. -
Run
Docker Desktop» Search ourpre-installed caching severas Docker Image with the keywordflbox/fl-cache. -
From
Imagesmenu » Run the downloadedflbox/fl-cache Docker Imageto createDocker Container(only for the first run). Remember to expose connection ports11211and6379for the newDocker ContainerfromOptional SettingswhenRun a new container(also required only for the first run), other settings no need to config. You can name the new container asFL-CACHEor any name you want. - If you don't run our software immediately after this, you can stop the recent created
Docker Container. -
From the next run, only need to start
Docker Desktop» Click run the createdDocker ContainerfromContainersmenu » Then run our software. -
Here is the recorded video for above steps:
-
Download
-
From our website »
Members Area»Download Software» Download filescrapegmaps.zipthen unzip the downloaded file (You can only access after subscribed the software). -
From the unzipped folder » Open & Edit file
config.iniwith any Text editor:-
From
[general]config section » replace default config ofcache_serverIP with your caching server IP (which installedRedisserver andMemcachedserver), addcache_passwordif your installedRedisserver require an authentication password (example:cache_password = Your_Password). Please only do this step if you don't use ourpre-installed cachingserver (See details). -
From
[scrapegmaps]config section » Replace the default config of maximum scrape threads number (threads = 100) by your computer CPU threads number if the default configuration is lower. - Save the edited file.
-
From
-
From the unzipped folder » Go to folder
txt» Open & Edit filescrapegmaps-keywords.txtwith any Text editor:-
Replace the sample searching keywords with your targeted product name or industry name and targeted location, each keyword in
one line and inside quote. Example:
"Hair Salon in London, United Kingdom"
"Hair Salon in Manchester, United Kingdom"
"Hair Salon in Leeds, United Kingdom"
... -
Trick to scrape maximum data: When you search in Google Maps, they only return maximum 20 results for a searching location,
you can scroll the searched results column to get more, but they also only return maximum more 100~200 results, even when
that location have more data. Our trick to get more data is searching by small administrative area locations (ward,
district, borough, street) instead of large administrative area locations (city, town, province, state, region). You can
find the cities database and its smaller administrative areas from
https://www.citypopulation.de/en and other similar
websites.
Example:
"Hair Salon in Barking and Dagenham, London, United Kingdom"
"Hair Salon in Barnet, London, United Kingdom"
"Hair Salon in Bexley, London, United Kingdom"
... - Please remember that you will get more results with more keywords. Our software support you to scrape data from tens of thousands, hundreds of thousands or even millions keywords in one task. Just add the keywords and leave it run one week, one month or even more. You can access the scraped database to get scraped data at any time you want, even while scrape task still running without affect the running task, no need to pause or stop it.
- Save the edited file.
-
Replace the sample searching keywords with your targeted product name or industry name and targeted location, each keyword in
one line and inside quote. Example:
-
From the unzipped folder » Go to folder
txt» Open & Edit fileproxies_http.txtwith any Text editor:- Replace sample
HTTP proxywith yourHTTP proxy, each proxy in one line. -
Allowed proxy format:
ipv4:port(
user:password@ipv4:port
user:password:ipv4:port*
ipv4:port:user:password*
*) Proxy user or proxy password must contain at least a latin character. -
SCRAPEGMAPS requires
HTTP proxyso please use onlyHTTP proxy, if you add other proxy types, the software will not work. It protects your real IP address will not be blacklisted by Google and make sure our scrape process will not be stopped by Google's bot detector. - Because proxy will be used throughout the scraping process, so it requires high speed and stable (99% uptime) proxy so please use ISP/Datacenter proxy with the same your location, and unlimited bandwidth if possible (if you use limited bandwith package, the software will be stopped when all added proxy are out-of-bandwidth, and you need to restart it after recharged proxy bandwidth).
- Our software will auto assign proxy to each thread and check proxy regularly (if any proxy of a thread died, it will change to another proxy). But this process will take long time if have a proxy died because it will check 3 times and wait until proxy timeout on each check to confirm proxy died. So please make sure all proxy are live before add to the software. You can use our free tool to check proxy before run: https://flbox.com/free-tools/check -proxy.
- Good proxy providers are suggested: oxylabs.io, rayobyte.com, etc... and other good proxy providers if you know.
- The number of proxies to use should be the same number of scraping threads. If less than, it will still work because many threads can use a same proxy, but it is not recommended.
- After added your proxy, please save the file.
- Replace sample
-
Run your own installed caching server or our
pre-installed caching server(which can run inDocker Container- See the detail here). -
After configured the software as above steps and run caching server, go to the software unzipped folder and run our software using
file
run.bat(double-click on it) -
Enter
campaign name(It will save the scraped data into database file with namecampaign_name.dbinsidedbfolder which inside software unzipped folder) -
In the first run, the software will ask you to enter your email address which have registered on our website and subscribed to
SCRAPEGMAPSsoftware for registration, please enter it. -
The software may ask you to restore a previous task (with the same
campaign name) if previous task crashed or stopped with any reason before it completed. Please:
-
Enter 1 if you want to run a new task with the same
campaign name, it will continue to write data to the database file with the samecampaign name. - Enter 2 if you want to restore previous crashed/stopped task as the same state of previous task before it crash/stopped, same state means it will continue scrape uncompleted keywords from the same assigned threads as previous run, completed threads from previous will not be restored. For example, from your last run all keywords assigned to 24 threads but only 14 threads completed its work and the software crashed/stopped, this restore option will continue run only 10 uncompleted threads.
- Enter 3 if you want to restore previous crashed/stopped task with the new state, it will re-assign unscraped keywords to all of your configured threads. Same example as the above option, instead of continue 10/24 uncompleted threads, it will re-assign unscraped keywords to all 24 threads. With this option, it will harder for us to debug the software if have any error, but it will boost the speed of uncompleted task. You can also choose option 3 if option 2 not work.
-
Enter 1 if you want to run a new task with the same
-
In the first run, Windows Firewall will ask you to allow access for the built-in web browser of SCRAPEGMAPS software, please allow it:
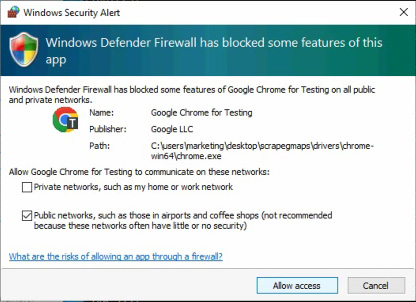
- Wait until the software start scrape the data to confirm it work normally (you can see scraped business name, their phone number and website (if available) on the console window), after that, you can leave it run. Sometimes you should check again the console window to make sure no problem happened if you are running a long task.
-
See our video instruction here:
-
From our website »
Members Area»Download Software» Download filescrapewebs.zipthen unzip the downloaded file (You can only access after subscribed the software). -
From the unzipped folder » Open & Edit file
config.iniwith any Text editor:-
From
[general]config section » replace default config ofcache_serverIP with your caching server IP (which installedRedisserver andMemcachedserver), addcache_passwordif your installedRedisserver require an authentication password (example:cache_password = Your_Password). Please only do this step if you don't use ourpre-installed cachingserver (See details). -
From
[scrapewebs]config section » Replace the default config of maximum scrape threads number (threads = 100) by 300% of your computer CPU threads number if the default configuration is lower. - Save the edited file.
-
From
-
From the unzipped folder » Go to folder
txt» Open & Edit filescrapewebs-urls.txtwith any Text editor:-
Replace the sample scraping URLs with your target scraping & extracting URLs, each URL in one line. Example:
https://www.myhairandbeautysalon.co.uk/
http://www.elegancesalons.co.uk/
http://www.samolgarhair.co.uk/
... - Please remember that you will get more results with more URLs. Our software support you to scrape & extract data from tens of thousands, hundreds of thousands or even millions URLs in one task. Just add the URLs and leave it run one week, one month or even more. You can access the scraped database to get scraped data at any time you want, even while scrape & extract task is still running without affect the running task, no need to pause or stop it.
- Save the edited file.
-
Replace the sample scraping URLs with your target scraping & extracting URLs, each URL in one line. Example:
-
From the unzipped folder » Go to folder
txt» Open & Edit fileproxies_http.txtwith any Text editor:- Replace sample
HTTP proxywith yourHTTP proxy, each proxy in one line. -
Allowed proxy format:
ipv4:port(
user:password@ipv4:port
user:password:ipv4:port*
ipv4:port:user:password*
*) Proxy user or proxy password must contain at least a latin character. - SCRAPEWEBS doesn't require proxy to run, you can scrape & extract website direct with your IP address. But we suggest you to scrape & extract websites with proxy to maximize scraping & extracting results, make sure you will never miss any chance to scrape & extract data, it because many websites are using the same CDN service like CloudFlare, KeyCDN,... to protect them from scraping bot: if those CDN services recorded too many connections from your IP address to too many websites which protected by them in a time, they know that a bot are running from your IP address and blacklist your IP address, then if your IP address was blacklisted, when you continue to connect to other websites which use those CDN service, it will ask you to verify you are not a bot, our software cannot pass the verification and will not scrape & extract those websites, it will reduce the number of results which you can scrape & extract. So proxy is strongly recommend to use.
- The number of proxies to use should be the same number of scraping & extracting threads. If less than, it will still work because many threads can use a same proxy, but it is not recommended.
-
SCRAPEWEBS use
HTTP proxyso please use onlyHTTP proxy, if you add other proxy types, the software will not work. - Because proxy will be used throughout the scraping & extracting process, so it requires high speed and stable (99% uptime) proxy so please use ISP/Datacenter proxy with the same your location, and unlimited bandwidth if possible (if you use limited bandwith package, the software will be stopped when all added proxy are out-of-bandwidth, and you need to restart it after recharged proxy bandwidth).
- Our software will auto assign proxy to each thread and check proxy regularly (if any proxy of a thread died, it will change to another proxy). But this process will take long time if have a proxy died because it will check 3 times and wait until proxy timeout on each check to confirm proxy died. So please make sure all proxy are live before add to the software. You can use our free tool to check proxy before run: https://flbox.com/free-tools/check -proxy.
- Good proxy providers are suggested: oxylabs.io, rayobyte.com, etc... and other good proxy providers if you know.
- After added your proxy, please save the file.
- Replace sample
-
Run your own installed caching server or our
pre-installed caching server(which can run inDocker Container- See the detail here). -
After configured the software as above steps and run caching server, go to the software unzipped folder and run our software using
file
run.bat(double-click on it) -
Enter
campaign name(It will save the scraped data into database file with namecampaign_name.dbinsidedbfolder which inside software unzipped folder) -
In the first run, the software will ask you to enter your email address which have registered on our website and subscribed to
SCRAPEWEBSsoftware for registration, please enter it. -
The software may ask you to restore a previous task (with the same
campaign name) if previous task crashed or stopped with any reason before it completed. Please:
-
Enter 1 if you want to run a new task with the same
campaign name, it will continue to write data to the database file with the samecampaign name. - Enter 2 if you want to restore previous crashed/stopped task as the same state of previous task before it crash/stopped, same state means it will continue scrape & extract uncompleted URLs from the same assigned threads as previous run, completed threads from previous will not be restored. For example, from your last run all URLs assigned to 24 threads but only 14 threads completed its work and the software crashed/stopped, this restore option will continue run only 10 uncompleted threads.
- Enter 3 if you want to restore previous crashed/stopped task with the new state, it will re-assign unscraped & unextracted URLs to all of your configured threads. Same example as the above option, instead of continue 10/24 uncompleted threads, it will re-assign unscraped & extracted URLs to all 24 threads. With this option, it will harder for us to debug the software if have any error, but it will boost the speed of uncompleted task. You can also choose option 3 if option 2 not work.
-
Enter 1 if you want to run a new task with the same
-
The software will continue ask you to confirm the URLs source for scraping and extracting, please:
-
Enter 1 if you want to scrape & extract website URLs which added into file
txt/scrapewebs-urls.txtas the above instruction. -
Enter 2 if you want to scrape & extract website URLs which scraped from
SCRAPEGMAPSsoftware. It requires the enteredcampaign namemust be same with the file name*.db(without '.db') which saved fromSCRAPEGMAPSsoftware, also requires you to do some steps before run the software:
-
Move all files and folders extracted from
scrapewebs.zipto the folder which extracted fromscrapegmaps.zip, exclude filesconfig.ini,run.bat,txt/proxies_http.txt, and*.dbfiles indbfolder which have the same name as*.dbfiles indbfolder inside the destination folder. -
Open file
scrapegmaps/config.iniand filescrapewebs/config.iniwith a Text editor for editing. Fromscrapewebs/config.ini, copy[scrapewebs]section and all configuration lines under it to end of filescrapegmaps/config.ini. Save and close files. -
Rename file
scrapegmaps/run.battoscrapegmaps/run-scrapegmaps.bat, rename filescrapewebs/run.battoscrapewebs/run-scrapewebs.bat, then copyrun-scrapewebs.battoscrapegmapsfolder. -
Open file
scrapegmaps/txt/proxies_http.txtand filescrapewebs/txt/proxies_http.txtwith a Text editor for editing. Copy proxies fromscrapewebs/txt/proxies_http.txtwhich is not duplicated to end of filescrapegmaps/txt/proxies_http.txt. Make sure no duplicated proxies and no empty line in filescrapegmaps/txt/proxies_http.txt. Save and close files. -
Rename files
*.dbfromscrapewebs/dbfolder which have the same name with*.dbfiles inscrapegmaps/dbfolder. Move all*.dbfromscrapewebs/dbfolder toscrapegmaps/dbfolder. - Rename folder
scrapegmapstoscrapedata. - Run
SCRAPEWEBSsoftware using filescrapedata/run-scrapewebs.bat.
-
Move all files and folders extracted from
-
Enter 1 if you want to scrape & extract website URLs which added into file
-
The software will continue ask you to confirm using proxy for scraping and extracting, please:
- Enter Y if you use proxy for scraping & extracting
- Enter N if you want to scrape & extract website URLs direct with your IP address
- Wait until the software start scrape and extract the data to confirm it work normally: you can see the number of email (EM), phone (PN), social links (FB, IG, LI, TW, etc...) which scraped and extracted on the console window, after that, you can leave it run. Sometimes you should check again the console window to make sure no problem happened if you are running a long task.
-
See our video instruction here:
-
From our website »
Members Area»Download Software» Download fileverifyemails.zipthen unzip the downloaded file (You can only access after subscribed the software). -
From the unzipped folder » Open & Edit file
config.iniwith any Text editor:-
From
[general]config section » replace default config ofcache_serverIP with your caching server IP (which installedRedisserver andMemcachedserver), addcache_passwordif your installedRedisserver require an authentication password (example:cache_password = Your_Password). Please only do this step if you don't use ourpre-installed cachingserver (See details). -
From
[verifyemails]config section » Replace the default config of maximum scrape threads number (threads = 100) by your computer CPU threads number if the default configuration is lower. - Save the edited file.
-
From
-
From the unzipped folder » Go to folder
txt» Open & Edit fileverifyemails-list.txtwith any Text editor:-
Replace the sample verifying email addresses with your target verifying email addresses, each email in one line.
Example:
[email protected]
[email protected]
[email protected]
... - You can verify any email addresses as you want, it is unlimited. Our software support you to verify from tens of thousands, hundreds of thousands or even millions email addresses in one task. Just add the email addresses and leave it run several days, one week, one month or even more. You can access the verified database to get verified email addresses at any time you want, even while verification task is still running without affect the running task, no need to pause or stop it.
- Save the edited file.
-
Replace the sample verifying email addresses with your target verifying email addresses, each email in one line.
Example:
-
From the unzipped folder » Go to folder
txt» Open & Edit fileproxies_socks5.txtwith any Text editor:- Replace sample
SOCKS5 proxywith yourSOCKS5 proxy, each proxy in one line. -
Allowed proxy format:
ipv4:port(
user:password@ipv4:port
user:password:ipv4:port*
ipv4:port:user:password*
*) Proxy user or proxy password must contain at least a latin character. -
VERIFYEMAILS requires
SOCKS5 proxyso please use onlySOCKS5 proxy, if you add other proxy types, the software will not work. It protects your real IP address will not be blacklisted by Email servers and maximize the number of verified email addresses (If the IP address used for verify email addresses had been blacklisted, we cannot check email addresses are exist or not). - The number of proxies to use should be the same number of verifying threads. If less than, it will still work because many threads can use a same proxy, but it is not recommended because IP addresses of proxies may be got blacklisted quickly.
- Because proxy will be used throughout the verifying process, so it requires high speed and stable (99% uptime) proxy so please use ISP/Datacenter proxy with the same your location. The email verifying process doesn't cost many bandwidth, so you don't need to use unlimited-bandwidth proxy package.
- Our software will auto assign proxy to each thread and check proxy regularly (if any proxy of a thread died, it will change to another proxy). But this process will take long time if have a proxy died because it will check 3 times and wait until proxy timeout on each check to confirm proxy died. So please make sure all proxy are live before add to the software. You can use our free tool to check proxy before run: https://flbox.com/free-tools/check -proxy.
-
As above mentioned, clean proxies are required for verifying email, so you can use our free tool to check blacklist of IP
addresses of proxies: https://flbox.com/free-tools/check-blacklist. If the total
blacklisted number is less than 15 and is not blacklisted by
SPAM SPAMRATS,SPAMSOURCES FABEL,B BARRACUDACENTRAL,ALL SPAMRATS, that means the IP address of proxy is clean. - Good proxy providers are suggested: oxylabs.io, rayobyte.com, etc... and other good proxy providers if you know.
- After added your proxy, please save the file.
- Replace sample
-
Run your own installed caching server or our
pre-installed caching server(which can run inDocker Container- See the detail here). -
After configured the software as above steps and run caching server, go to the software unzipped folder and run our software using
file
run.bat(double-click on it) -
Enter
campaign name(It will save the scraped data into database file with namecampaign_name.dbinsidedbfolder which inside software unzipped folder) -
In the first run, the software will ask you to enter your email address which have registered on our website and subscribed to
VERIFYEMAILSsoftware for registration, please enter it. -
The software may ask you to restore a previous task (with the same
campaign name) if previous task crashed or stopped with any reason before it completed. Please:
-
Enter 1 if you want to run a new task with the same
campaign name, it will continue to write data to the database file with the samecampaign name. - Enter 2 if you want to restore previous crashed/stopped task as the same state of previous task before it crash/stopped, same state means it will continue verifying uncompleted email addresses from the same assigned threads as previous run, completed threads from previous will not be restored. For example, from your last run all email addresses are assigned to 24 threads but only 14 threads completed its work and the software crashed/stopped, this restore option will continue run only 10 uncompleted threads.
- Enter 3 if you want to restore previous crashed/stopped task with the new state, it will re-assign unverified email addresses to all of your configured threads. Same example as the above option, instead of continue 10/24 uncompleted threads, it will re-assign unverified email addresses to all 24 threads. With this option, it will harder for us to debug the software if have any error, but it will boost the speed of uncompleted task. You can also choose option 3 if option 2 not work.
-
Enter 1 if you want to run a new task with the same
-
The software will continue ask you to confirm the email addresses source for verifying, please:
-
Enter 1 if you want to verify email addresses which added into file
txt/verifyemails-list.txtas the above instruction. -
Enter 2 if you want to verify email addresses which scraped & extracted from
SCRAPEWEBSsoftware. It requires the enteredcampaign namemust be same with the file name*.db(without '.db') which saved fromSCRAPEWEBSsoftware, also requires you to do some steps before run the software:
-
Move all files and folders extracted from
verifyemails.zipto the folder which extracted fromscrapewebs.zip, exclude filesconfig.ini,run.bat, and*.dbfiles indbfolder which have the same name as*.dbfiles indbfolder inside the destination folder. -
Open file
scrapewebs/config.iniand fileverifyemails/config.iniwith a Text editor for editing. Fromverifyemails/config.ini, copy[verifyemails]section and all configuration lines under it to end of filescrapewebs/config.ini. Save and close files. -
Rename file
scrapewebs/run.battoscrapewebs/run-scrapewebs.bat, rename fileverifyemails/run.battoverifyemails/run-verifyemails.bat, then copyrun-verifyemails.battoscrapewebsfolder. -
Rename files
*.dbfromverifyemails/dbfolder which have the same name with*.dbfiles inscrapewebs/dbfolder. Move all*.dbfromverifyemails/dbfolder toscrapewebs/dbfolder. - Rename folder
scrapewebstoscrapedata. - Run
VERIFYEMAILSsoftware using filescrapedata/run-verifyemails.bat.
-
Move all files and folders extracted from
-
Enter 1 if you want to verify email addresses which added into file
- Wait until the software start verify the email addresses list to confirm it work normally: you can see the verify result on the console window, after that, you can leave it run. Sometimes you should check again the console window to make sure no problem happened if you are running a long task.
-
See our video instruction here:
-
SCRAPEGMAPS,SCRAPEWEBS, andVERIFYEMAILSsoftware save the scraped/extracted/verified data intoSQLite3 database filesare*.dbfiles inside folderdb. You can easy open data files usingDB Browsersoftware then copy scraped/extracted/verified data to Excel, Google Sheets, or any Text Editor software for using those data. You can view this step in the recorded instruction video of previous steps. -
You can download & install
DB Browserfrom: https://sqlitebrowser.org/dl/
If you meet any difficult while install and using our software, you can contact us through email
[email protected] or Whatsapp
number: +32.460-242-686. We are always ready to help you to install and use the
software.